Coding A Web Browser - C using GCC
HTTP Get Request internet web client
Description
When a web browser loads a page it starts by making an HTTP request to the domain address provided. Then it must process the xml, css and javascript eventually rendering the page. Here we only make the HTTP request. We start with the stock tcp/ip code available for linux from the netdb.h header. Then we write the HTTP protocol string formatting. Once we successfully make a request, the web server will write a response, and we print that response to the console.
There are five versions here. Download links are at the very bottom of this page. The first version is the HTTP protocol without encryption. In today's internet marketplace, most websites are exclusively HTTPS services including google.com. However, there are plenty websites that still do serve the HTTP protocol. One such website is example.com. You can try the HTTP get request client offerred here for the domain example.com but it will not work with google.com. The next versions build up to using the HTTPS protocol for TLS(transport layer security) using OpenSSL. OpenSSL uses buffered I/O built on top of the standard TCP/IP socket. Before trying to code a working HTTPS web client we work towards a working HTTP buffered I/O code base.
Buffered I/O is available to the C programmer by including the "openssl/bio.h" header. The second version included here is a working HTTP buffered I/O code base. However, it does not actually do any buffering. That is, it uses the OpenSSL buffered socket but only reads from it once. It is all coded in a single file.
The third version breaks up that code into multiple files making it a library and the read function is updated with a multiple read algorithm. This library version actually takes advantage of the buffering socket provided by theOpenSSL library. TLS is still yet to come.
The forth version uses the HTTPS protocol. It uses a self signed certificate. The cert filename is hardcoded as "TrustStore.pem" expecting it to reside in the current directory as the program executable "a.out". All the code is in a single file. It uses OpenSSL's buffered I/O but only reads once. The fifth and final version here breaks up the code into multiple files making it a library and the read function is updated with a multiple read algorithm.
Usage
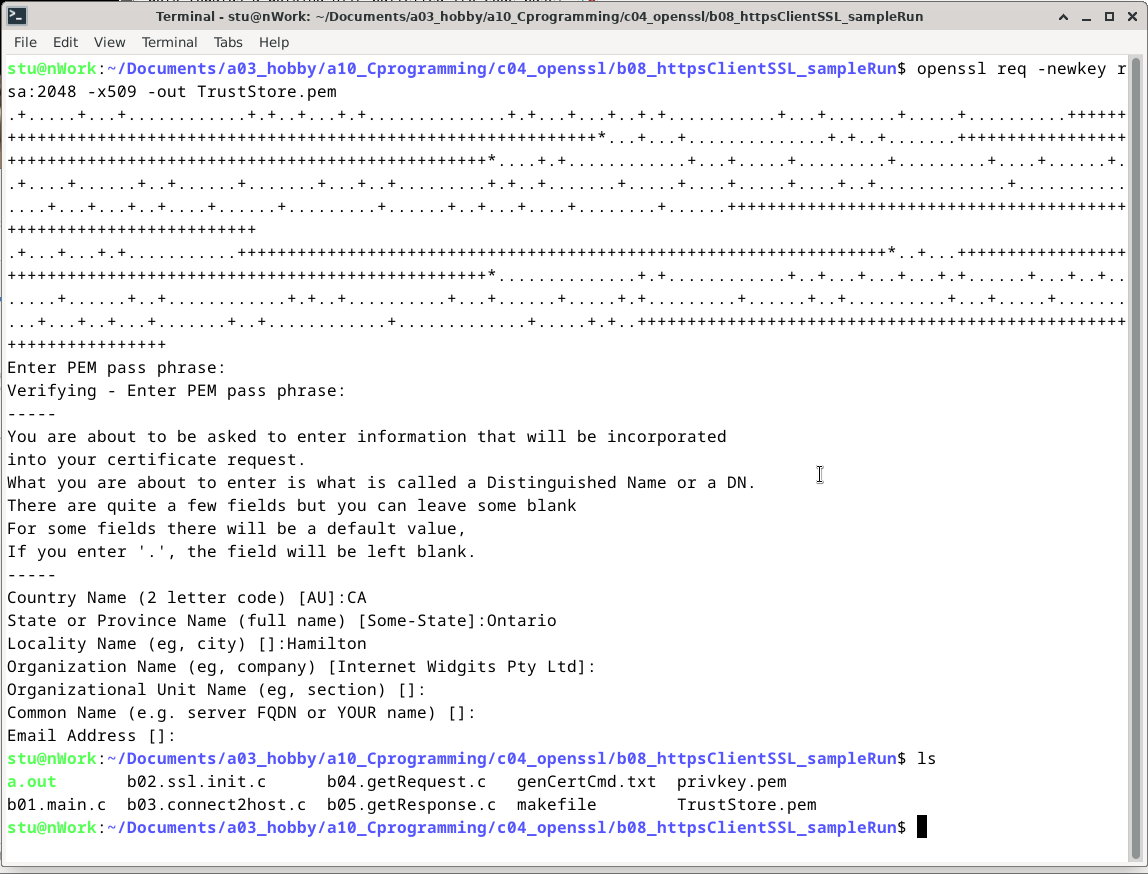
Simply run the make file. You will need to install the OpenSSL header package named libssl-dev on Debian Linux systems. The HTTPS versions, versions 4 & 5 require a self signed certificate that can be generated by using the OpenSSL tool itself.
$openssl req -newkey rsa:2048 -x509 -out TrustStore.pem
You will be prompted to enter a password. It will use it for generating the certificate.
DEMO
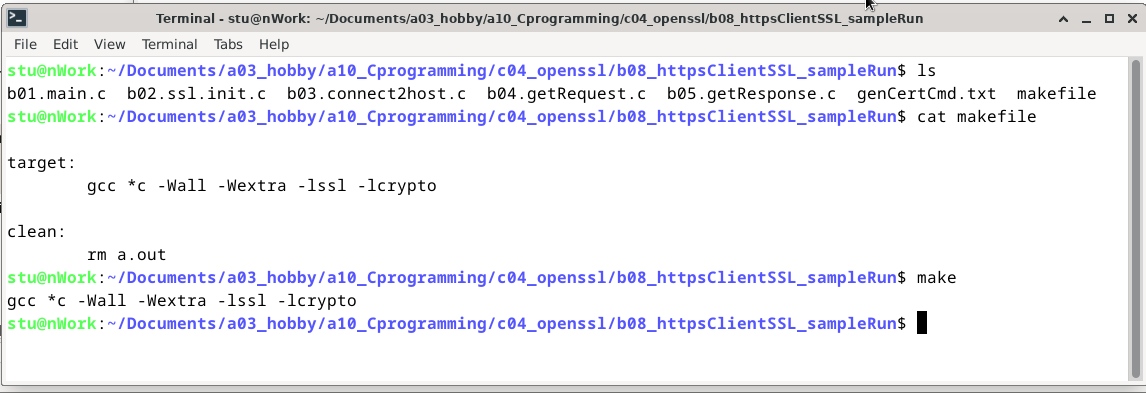
Compiling:
Generating OpenSSL x509 self signed cert:
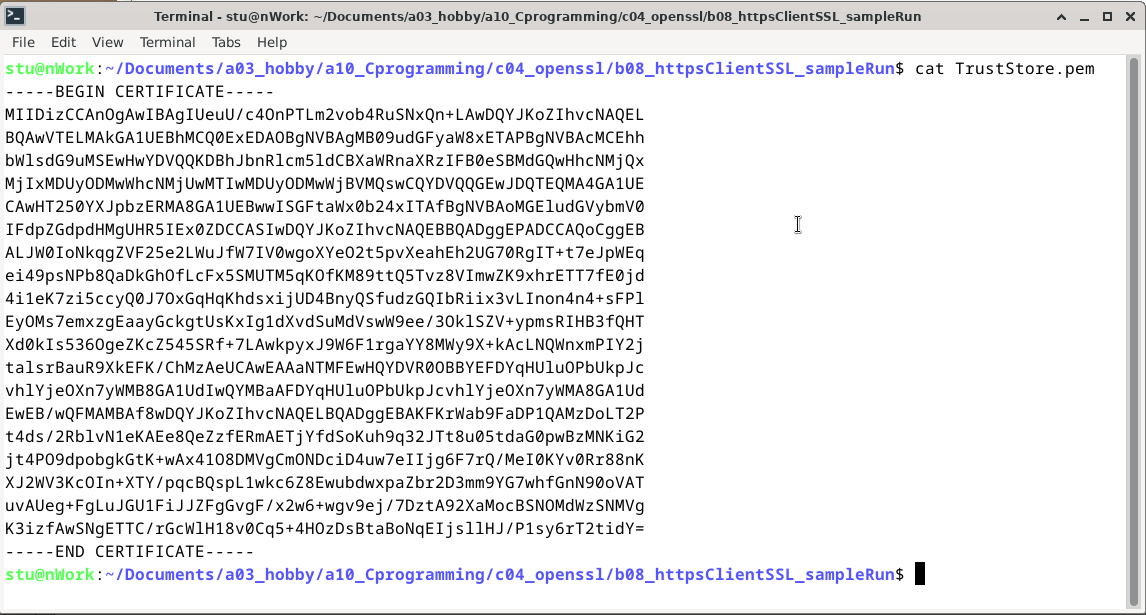
Self signed cert named "TrustStore.pem" file contents:
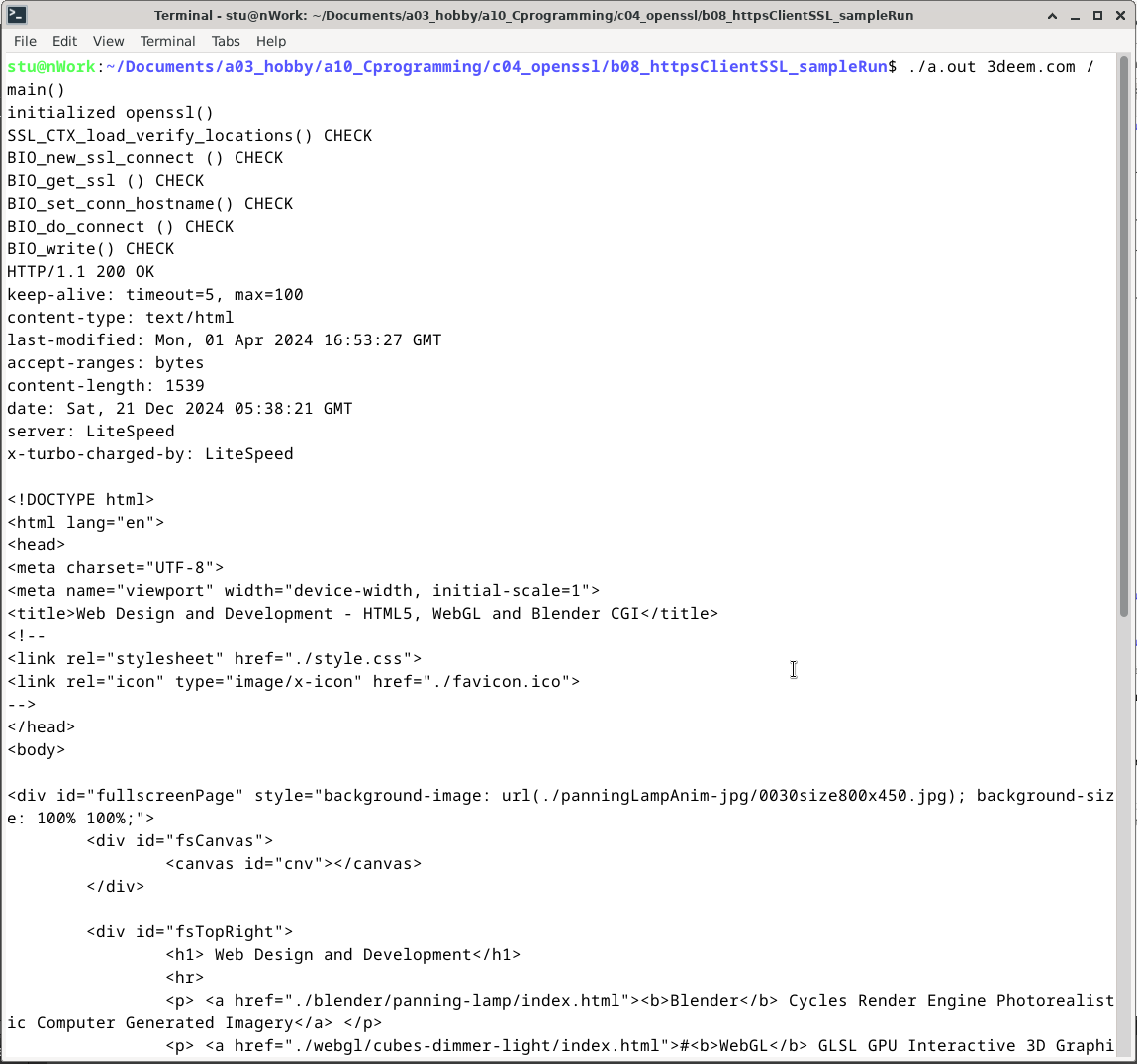
Sample run:
Click on any screenshot image above for a fullscreen view.
Final Notes
OpenSSL is great for not only providing TLS but also for it's buffered I/O capabilities. Buffering is important for critical systems that would have to deal with latency issues on any network. OpenSSL would benefit anyone interested in TLS and buffered socket communications.
On google.com, the fifth and final verion makes a secure connection but google returns a 301 Moved http response. On other websites you should get the html page as expected as you can see on the screenshot of the sample run in the demo section above.
Download
1. HTTP no buffering:
github.com/nadeemelahi/c_httpGetRequest
2. HTTP using a socket capable of buffering:
github.com/nadeemelahi/openSSL_BIO_httpGet_singleFile
3. HTTP with buffering(multiple read loop):
github.com/nadeemelahi/openSSL_BIO_httpGet_library
4. HTTPS with self signed cert but only single read on the socket:
github.com/nadeemelahi/openSSL_BIO_httpsGetRequest_selfSignedCert_singleFile_noBufferReadLoop
5. HTTPS with self signed cert and multiple read loop on the buffered I/O socket:
github.com/nadeemelahi/openSSL_BIO_httpsGetRequest_library_selfSignedCert